
Classification vs Regression
In machine learning, there are 2 ways study data and they are:
- Unsupervised learning: the model learns from unlabeled data
- Supervised learning: the model learns from labeled data
This blog is divided into 3 parts; they are:
- What is classification in machine learning?
- What is regression?
- Classification vs Regression
What is classification in machine learning?
Classification is a type of supervised learning, its the task of approximation of a mapping function from an input variable (x) to a discrete output variable (y) called a label or a class.
The mapping function predicts the class or label for a given query. for example, a customer can give rating to an item they bought and your models function maps this review to a class of either "positive" or "negative".
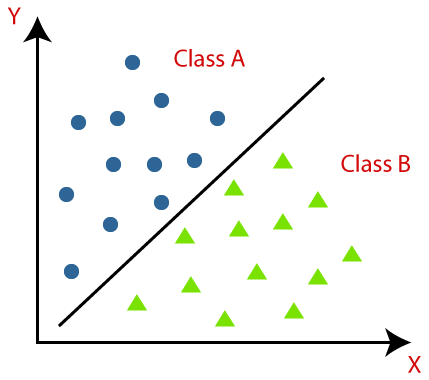
Some classification terminologies:
Classifier: An algorithm that is used to assign a label to the input data.
Multi-class classification: There are more than 2 classes but each query is assigned to only one class.
Multi-label classification: Each query can be assigned to more than one class.
Evaluate: Showing the models accuracy.
Examples of classification algorithms:
- Naive bayes classifier
- K-nearest neighbor
- Decision tree
- Random forest
What is regression in machine learning?
Regression analysis is a crucial concept in machine learning, it is a type of supervised learning.
It's the task of approximation of a mapping function from input (x) to continuous output (y) , it is used to understand how a dependent variable changes with respect to an independent variable when other independent variables are fixed.
In regression we plot a graph that best-fits the given data points and the model makes predictions based on this graph

Some regression terminologies:
Dependent variable: Main factor that we want to predict.
Predictor: The factors used to predict the dependent variables.
Overfitting: The model fits exactly on the training data, resulting in inaccurate results with unseen data.
Underfitting: The model is too simple or it needs more training time, underfitting is easier to detect because its behavior can be seen using the training data.
Outliers: An observation with very high or very low value compared to other observations, they should be avoided because they can alter with the result.
Examples of regression algorithms:
- Linear regression
- Random forest regression
- Support vector regression
- Logistic regression
Linear regression code snippet:
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
housing = fetch_california_housing()
X_train, X_test, y_train, y_test = train_test_split(housing.data, housing.target)
clf = LinearRegression()
clf.fit(X_train, y_train)
result=clf.predict(X_test)
expected=y_test
plt.figure(figsize=(4, 3))
plt.scatter(expected, result)
plt.plot([0, 50], [0, 50], '--k')
plt.axis('tight')
plt.xlabel('True price ($1000s)')
plt.ylabel('Predicted price ($1000s)')
plt.tight_layout()
output:
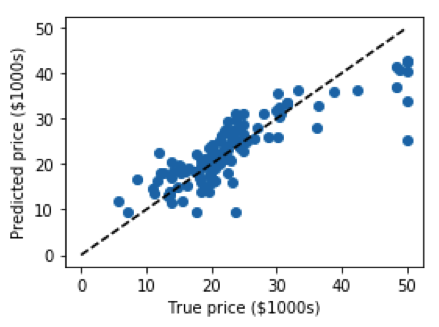
Generally, regression algorithms are used to predict continuous values like age, price, temperature, etc.
Classification vs Regression
| Regression | Classification | |
| Data type | predicted data is of continuous value ex: salary, price, age | predicted data is of discrete value ex: either "good" or "bad" |
| Calculation method | uses root mean square error (RMSE) | calculate accuracy to know the best fit for the dataset |
| Nature of prediction output | predicted data is ordered | predicted data is unordered |
| Algorithms |
|
|
Conclusion
These are some of the differences between regression and classification, in some cases an overlap can happen between the 2, for example:
- Classification algorithm may predict a continuous value that is in the form of a probability of a certain label.
- Regression algorithm can predict discrete value in the form of integer quantity.
because of this overlap, in some cases its possible to convert a regression problem into a classification problem and vice versa
Summary
In this short blog you learned:
- Predictive modeling is learning a mapping function from inputs to outputs
- Regression is prediction of continuous output
- Classification is prediction of discrete label output
- Khaled Gamal
- Mar, 20 2022