
Introduction on Computer Vision
Introduction to Computer
Vision
Computer Vision is a branch of Deep Learning and Artificial Intelligence in which people educate computers to observe and comprehend their surroundings. While humans and animals easily solve vision as a problem from a very young age, assisting robots in interpreting and perceiving their surroundings through vision remains mostly unresolved. Machine Eyesight is complicated at its heart due to the limited perception of human vision and the infinitely altering scenery of our dynamic environment. Since then, the history of computer vision has been peppered with landmarks produced by the fast development of picture capture and scanning tools, accompanied by the construction of cutting-edge image processing algorithms. Previously, computer vision was simply supposed to replicate human visual systems until we discovered how AI can complement its applications and vice versa. We may not recognize it every day, but computer vision applications in automotive, retail, banking and financial services, healthcare, and other fields are assisting us.
Working of CNN:- Artificial neural networks were wonderful for tasks that conventional machine learning algorithms couldn't handle, but they require a long time to train when processing images with fully linked hidden layers. As a result, CNN was utilized to decrease the size of pictures first using convolutional and pooling layers, before feeding the reduced input to fully connected layers.

Fig. CNN Architecture [1]

Fig. AlexNet Architecture [2]
VGGNet (2014): - VGGNet was created by the University of Oxford's VGG (Visual Geometry Group). Despite the fact that VGGNet came in second place, not first, in the classification challenge at the ILSVRC 2014, it still outperformed the prior Networks. VGGNet has 16 convolutional layers and a highly homogeneous design, making it quite attractive. AlexNet-like (3x3 convolutions), but with a lot more filters. Its primary purpose is to extract characteristics from photos. SSD, an object identification technique without completely linked layers, is based on VGG-16.

Fig. VGG Architecture [3]
ResNet(2015): - Kaiming He et alResidual .'s Neural Network (ResNet) won the ILSVRC 2015. On this dataset, it scored a top-5 error rate of 3.57 percent, which is better than human performance. It provides a 152-layer architecture that incorporates strong batch normalization and skips connections (gated units or gated recurrent units). The entire point of ResNet is to solve the problem of disappearing gradients. Vanishing gradients is an issue that happens in networks with a large number of layers when the weights of the initial layers cannot be updated accurately by backpropagation of the error gradient (the chain rule multiplies error gradient values lower than one and then, when the gradient error comes to the first layers, its value goes to zero).

Fig. ResNet Architecture [4]
Inception (2014): - The ILSVRC 2014 was won by GoogLeNet, which obtained a top-5
error rate of 6.67%. The network employs a CNN modeled by LeNet. Instead of
employing completely linked layers, its architecture includes 11 Convolution in
the center of the network and global average pooling at the network's
conclusion. It also employs the Inception module to have several sizes/types of
convolutions for the same input and stack all of the outputs. In addition, it
employs batch normalization, image distortions, and RMSprop. 1x1 convolution is
used as a dimension reduction module in GoogLenet to decrease computation.
Depth and breadth can be enhanced by lowering the computing bottleneck.
GoogLenet's architecture is based on a 22-layer deep CNN, but the number of
parameters is reduced from 60 million (AlexNet) to 4 million.
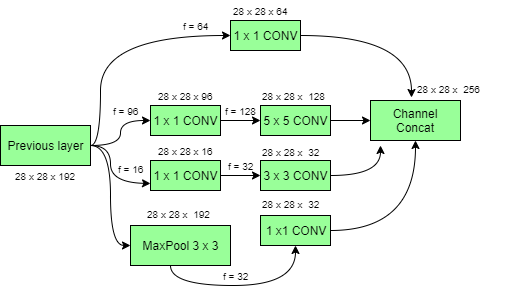
Fig. Inception Architecture [5]
All Credits Link: -
[1] https://www.researchgate.net/figure/A-generic-CNN-Architecture_fig1_344294512
[3] https://paperswithcode.com/method/vgg
[4] https://www.researchgate.net/figure/ResNet-architecture-with-atrous-convolution_fig2_328099227
[5] https://www.geeksforgeeks.org/ml-inception-network-v1/
- Vivek Kumar Verma
- Apr, 01 2022