
Understanding Supervised Learning easily !!
The Concept of Machine Learning:
At the turn of the 20th century, incredible advances in electronic technology paired with the theoretical tools of information theory and Boolean algebra (the mathematics of 1s and 0s) lead to the development of the first computers. These first age computers were slow and clunky compared to today's standard but were a technological marvel all the same. This got some creative and visionary minds thinking. What if human intelligence could be replicated by a computer? This sparked the birth of the field, Artificial Intelligence.
As the decades went on researchers realized that the designing of an intelligent machine wasn't at all a straightforward task. Many complications would always arise, as we don't have a complete understanding of human intelligence and consciousness in the first place. This is where machine learning came into the picture. Machine learning is concerned with the application and development of computer algorithms that become better at their task by learning from data. This is achieved by a combination of statistical learning, mathematical optimization and computational methods. The process usually involves splitting the data into training and testing sets. The model is fit on the training set and then the accuracy of its predictions is evaluated on the testing set, after which an optimization algorithm is employed to improve accuracy. It is usually an iterative process, where training, testing and optimization are carried out as many times as necessary.
Machine learning, being one of the key areas in computer technology today finds application in many fields which include medicine, computer vision, speech-to-text, voice recognition, self driving cars, and so on. As vital as it is today the field is expected to grow even larger in the next few years.
In the broadest sense, machine learning can be categorized into three types: supervised, unsupervised and reinforcement learning. As we will be discussing supervised learning we will only briefly touch on the other two.
In unsupervised learning the model is working with unlabeled data, and has to learn through finding patterns inherent in the data. Reinforcement learning uses a reward and punishment based approach to guide the model towards the most accurate predictions, it is viewed by some as the closest machine learning has come to true artificial intelligence.
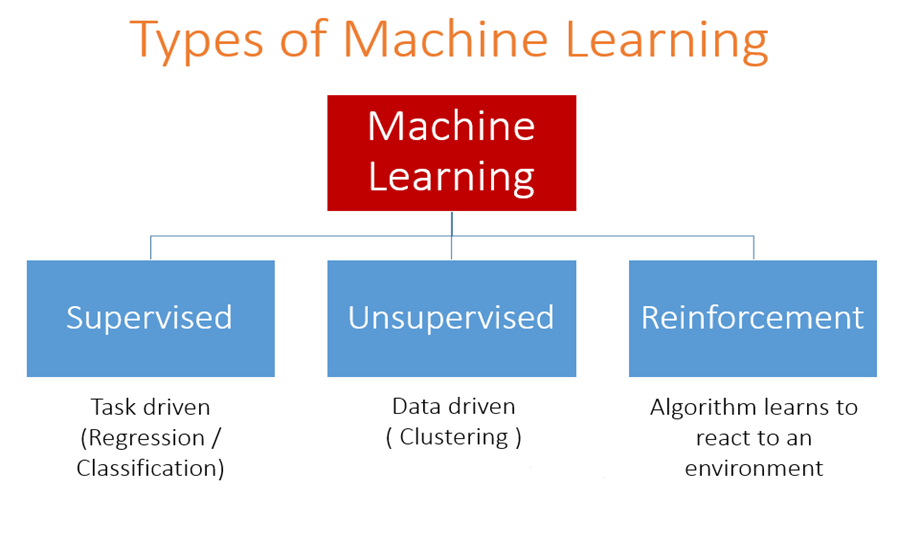
Supervised Learning:
Supervised learning involves training a model on a labelled data set, that is, there is a concept of dependent and independent variables. In the learning process, the model is trying to predict the dependent variable given certain values of the independent variables. It can also be conceptualized as knowing the relationship between the input and output of a given system. This is done by adjusting the weight of each input variable, which decides to what extent the input variable contributes to the output. Supervised learning can also be broadly classified based on the nature of the output data being discrete (having labels) or continuous (not having labels). Based on this we have classification and regression.
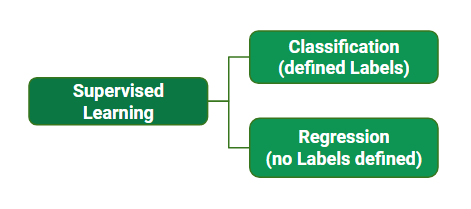
Regression:
This is a type of supervised learning in which the output has continuous values, that is, it can take on any value between a given range. Some scenarios requiring supervised learning are:
- Predicting temperature given atmospheric conditions such as humidity and wind speed.
- Predicting the price of an automobile given features such as fuel consumption and CO2 emission.
- Predicting industrial scale chemical reaction durations given initial conditions.
There are multiple types of regression algorithms based on two factors; the form of the regression function and the number of dependent variables. In Linear Regression, the output variable is modeled as a linear combination of the input variables plus a constant. In Polynomial Regression the output is a nonlinear polynomial of the input variables. We can also have Multivariate Linear Regression, in which there are multiple output variables.
In model evaluation, bias and variance are two very important metrics. Variance is a measure of how much the parameters of the model would change if different training sets were used. While bias, is a measure of how erroneous our model is due to learning non relevant patterns in our data. An ideal model is one which is low in bias and variance, but this is often impractical.
Classification:
In classification problems, we are concerned with mapping a discrete and usually categorical output variable to the input variables. Unlike regression, the prediction is done by assigning probabilities to the different classes. Some tasks requiring classification include:
- Predicting whether customers choose to purchase a product given the demographic.
- Predicting whether a patient has a disease or not using clinical test data.
- Object detection and image recognition.
There are a variety of classification algorithms, some commonly used ones are; Logistic Regression, Support Vector Machines, Decision Trees, Random Forests, Naïve Bayes and Nearest Neighbor Algorithms.
- Nasiru Mohammed Ibrahim
- Mar, 27 2022